The goal of this project is to build a movie recommendation system, using latest data scraped from GroupLens and The Movie Database. The GroupLens data was last updated on September 26, 2018. The dataset includes data from 283228 users between January 09, 1995 and September 26, 2018, and contains 27,753,444 ratings and 1,108,997 tag applications across 58,098 movies.
Data collection
Movie ids and information were taken from GroupLens and used to scraped movie data from The Movie Database using an API. The scraped data contain information about a movies name, cast, crew, release year, adult rating, poster, revenue and runtime amongst others. Following data cleaning and feature engineering, the dataset had 18 fields descibed below:
| Variable | Description |
|---|---|
| id | Movie ID in the TMDb |
| year | Movie release year |
| title | Movie title in english |
| runtime | Movie runtime in minutes |
| collection | Collection name, if applicable |
| genres | Movie genres |
| tagline | Movie tagline |
| overview | Plot overview |
| cast | Names of the first 5 cast members |
| director | Movie director name |
| producer | Movie producer(s) name |
| keywords | Movie’s keywords |
| adult | Movie’s adult rating (bool) |
| prod_comp | Name of production company/ies |
| languages | Languages spoken in the movie |
| popularity | Movie’s popularity on TMDb |
| vote_count | Number of users who rated the movie on TMDb |
| vote_avg | Movie’s average score on TMDb |
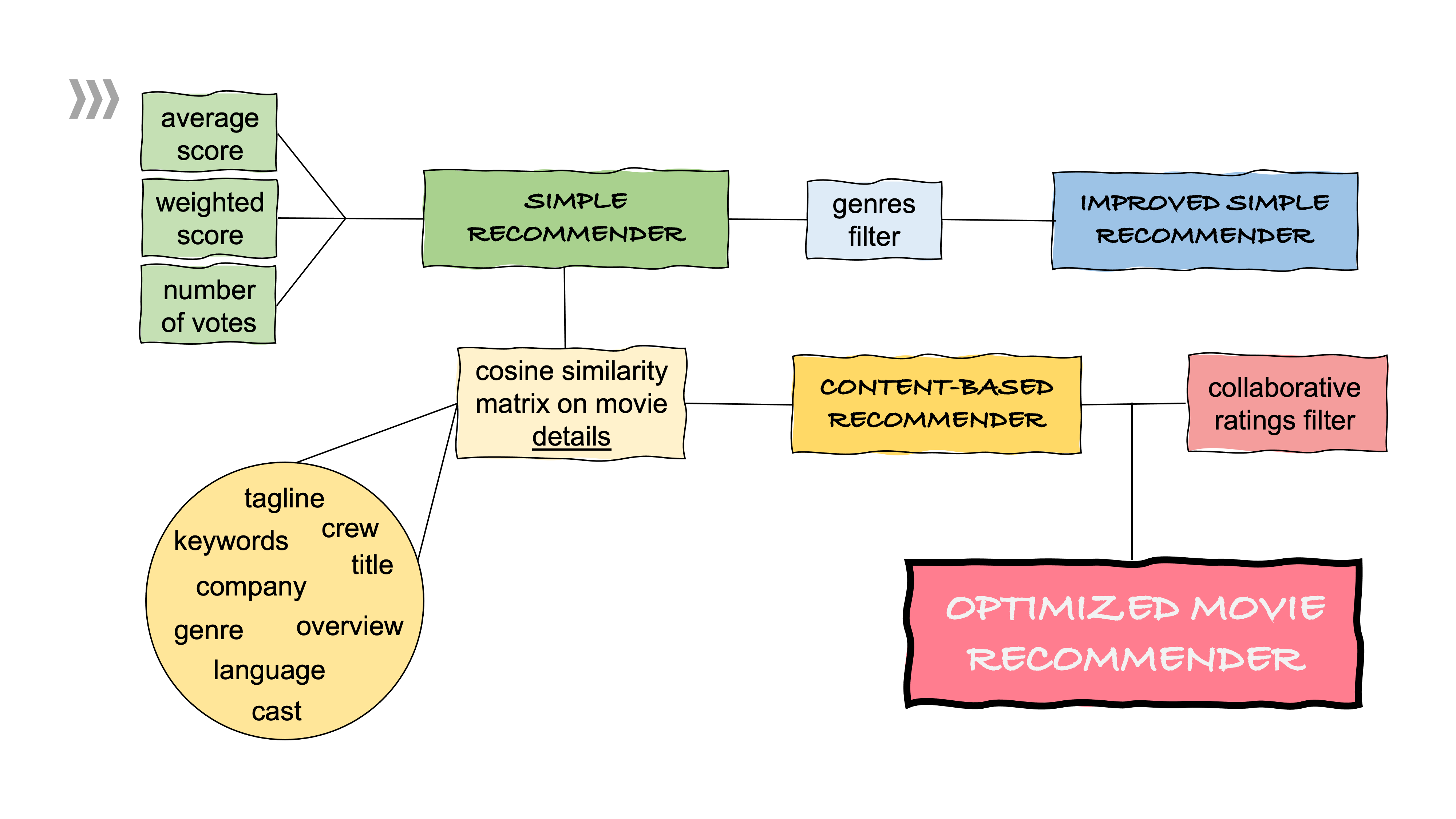
Optimization work flow