Hiring and training employees is an expensive process that requires capital, time and skills. On average, companies lose 1 - 2.5% of their total revenue on the time it takes to bring a new hire up to speed. Furthermore, companies spend 15 - 20% of the an employee’s salary to recruit a new candidate. Therefore, it might be beneficial for companies to predict which employees are likely to quit based on certain factors and take preemtive measures if possible.
Learn more about the cost of losing employees here
Project Summary
The goal of this project was to tackle employee attrition in the healthcare sector. Particularly, I wanted to answer two questions:
- Which employees are likely to leave?
- Can employee attrition be preemptively predicted?
To address these questions, I decided to train two machine learning models - an unsupervised model (clustering) to gain insight into different classes of attrited employes and a supervised model (classification) to predict employee attrition.
The data
The dataset explored in this project was curated by Kaggle user JohnM contains 35 fields and 1676 employee records. It contains demographics information on healthcare workers, including their gender, marital status, distance from work amongst others. It also contains the each employees’ compensation, ratings of different aspects of their working environment.
Conclusions: Clustering Analysis
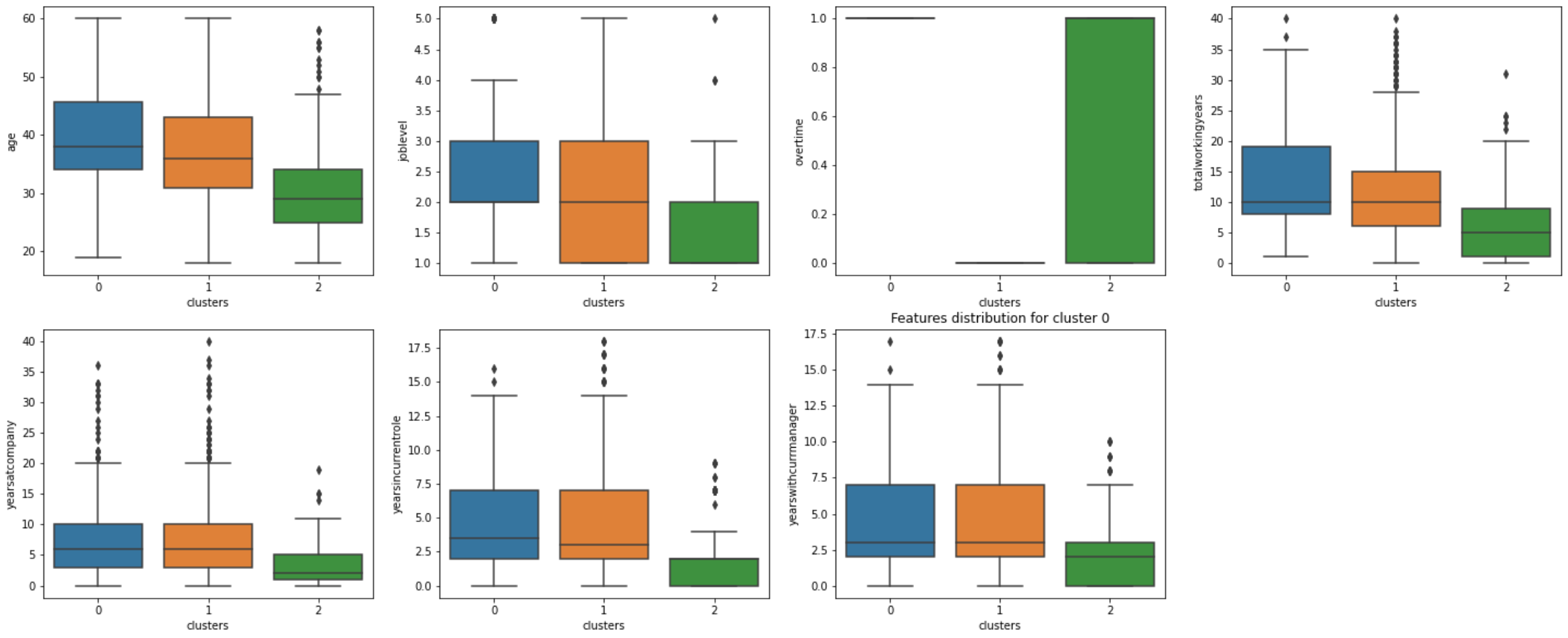
In general, employees who tend to leave their workplace (cluster 2) are younger (average age = 30 years old), entry-level personel that have not been working for a long time (with the hospital or elsewhere). Interestingly, overtime did not play a huge role in attrition, as the distribution of personel across the cluster is evenly split for this feature
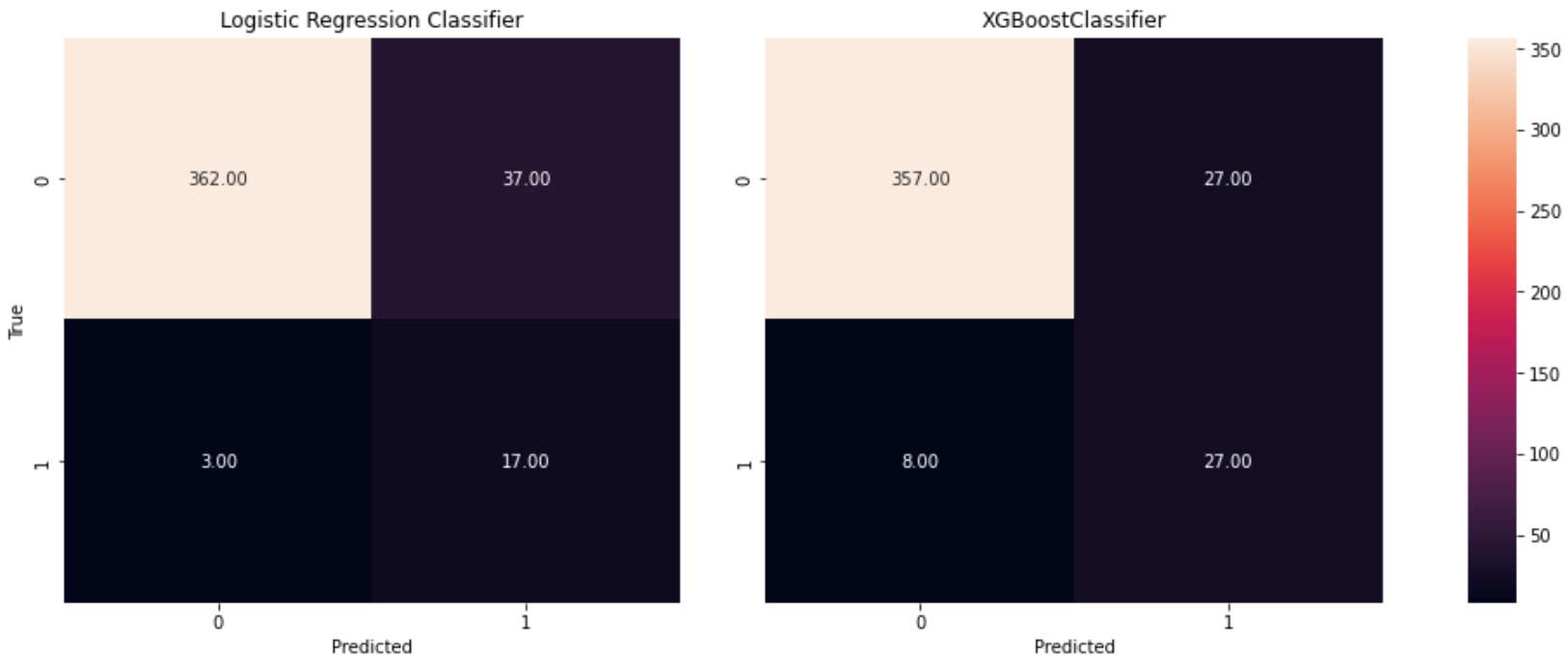
Conclusions: Employee Attrition Prediction
Two regression models were trained and evaluated in this project - a Logistic Regression Classifier and an XGBoost classifier. Overall, both classifiers performed well, with high accuracy scores (~90%). Nevertheless, the XGBoost model had better recall than the Logistic regression model, making it the recommended option for this analysis.